
Social Science Without Social Scientists
Social Science Without Social Scientists
Transcending the curse of dimensionality

Continuing on the theme of the format of social science outputs (is knowledge stored in the .pdf or the .csv?):
Machines can now directly encode and analyze sense data: we set up sensors, and then it's hands off. This data is incomprehensibly large. In the current mode of social science production, humans impose some structure on the data in order to render it comprehensible at the human scale. In practice, this means testing some theory of human behavior after “operationalizing” by checking whether a given pattern exists in some tiny subset of the data.
Physical location is a useful example. Because many people have helpfully agreed to carry a GPS on their person at all times, a researcher could have access to millions of datapoints every time the cell tower pings, far more data than we can process on our own.
The standard approach is to impose some structure on the data in order to test a theory, to generate knowledge. Famously, one research team used this data to show that mixed-partisan families were spending less time together on Thanksgiving. Starting with tens of billions of data points, they threw out the overwhelming majority in order to focus on something comprehensible: the duration, on Thanksgiving afternoon, that a cluster of cell phones was within a small number of feet from each other.
For contrast, consider the pre-digital act of measuring another brain. Researchers of opinion or behavior want to know what’s inside someone else’s brain. But the brain is too massive, too high-dimensional. A baseline technique for close to a century has been the use of fixed-choice surveys. These surveys distill the enormity of the brain into the “best answer” to a multiple choice question, which can then be analyzed statistically. The first choke point here is human communication; even if our only goal is expression, the amount of information per second we can communicate is vastly less than is in our brains. The second choke point is even worse: this outpouring of expression is reduced to a series of integers. For social science involving what’s in human brains, we cannot begin the process except at human scale; no machine sensors (yet?) can passively collect this data.
A final example, something I’ve develop in my relatively brief time as a practicing researcher in natural language processing. We used to get text data and then do some researcher-imposed artisanal crafting to make it usable. For example, the first step is generally to chunk up a text into individual words, which can then be transformed into a matrix upon which we can do statistics.. This fails for "multi-word expressions" like "White House"; treating that as two separate decreases performance. So I was trained to run a specific model that searches for these "MWEs" and see which ones jump out of the dataset at hand and then manually check them. These MWEs are then treated as single words.
Now, everyone runs text through BERT. No one knows how BERT works, but we know it works because it has access to more data than a human brain. They gave it all of Wikipedia; 2.5 billion words, as the sense data. BERT is unsupervised machine learning; supervised ML requires a human to give labels to the machine, but BERT just learns patterns from the raw data of human textual communication. BERT contains knowledge and an inhuman scale; we gain access to it when we use it for some other task (for example, it has already learned all MWEs and many other less-boutique relationships between words). From an inhuman perspective, a lot of knowledge is lost at the final step; but that doesn't matter, of course, because it ultimately does expand what humans can do.
To summarize these three examples. Opinion research begins with human-scale data. Human physical location and quantitative text analysis both start with massive, inhuman sense data. The former is transformed to human scale at the level of processing (or perhaps modeling), when the structure is imposed for hypothesis testing. Text analysis with BERT involves all the processing done at machine scale, unsupervised; it’s only at the stage of application that the human filter is applied.
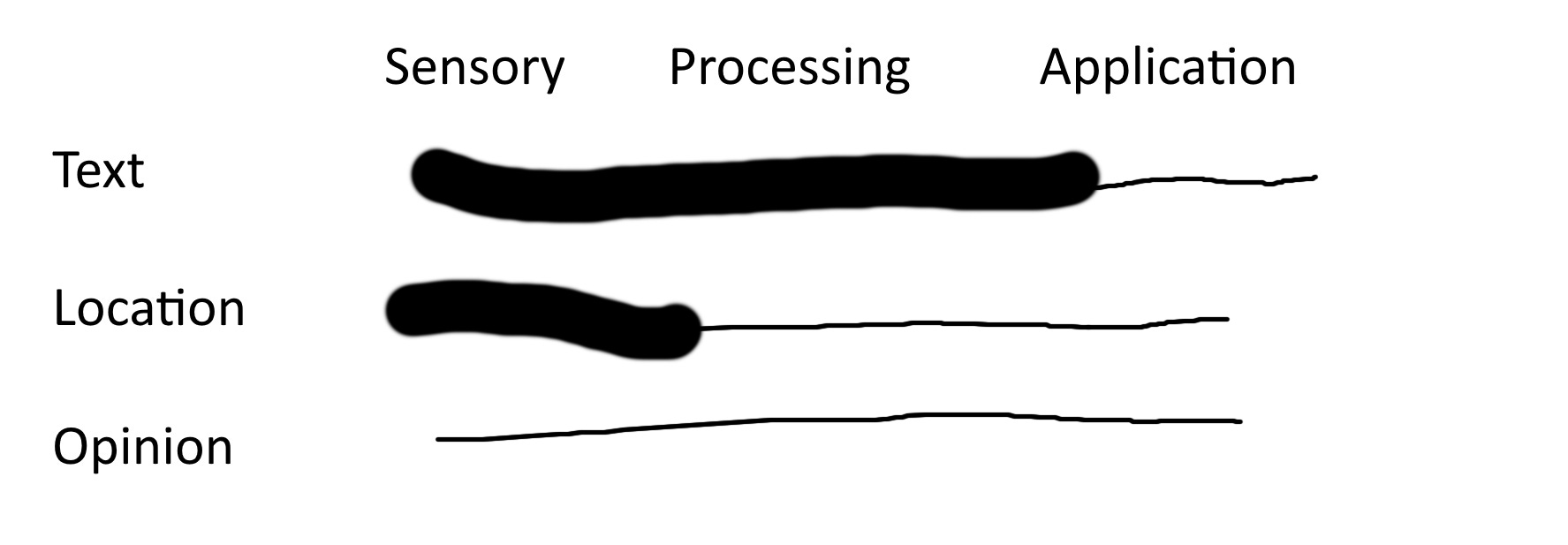
Human sensory capacity and cognition are choke points. The above figure and my framework thus far has been focused on knowledge production at the scale of a single project/publication. But meta-science is not about knowledge at this scale; we are interested in the aggregate output of social science.
As more of the nodes in individual projects become machines, we need to make the connections non-human as well. The format of the academic paper serves many sociological and pedagogical functions; decades ago, it was the cutting edge of knowledge storage and transmission. Today, however, the paper imposes human-cognition filters when trying to synthesize knowledge across projects. The advantages of BERT (and its cousins, which are merely awaiting the collection of more sensory data) will never be fully realized until these dimensionality filters are removed.
Yes, somebody still has to be there at the beginning designing the sensors, and somebody has to make the output human-comprehensible; at that point, it might well be synthesized with qualitative knowledge, or ethical values, or political power or whatever people want to do with it. But we have a lot of humans in the middle that are severely limiting the potential of this system of quantitative knowledge.
And we already have examples of end-to-end knowledge systems: Facebook’s recommendation algorithm. Facebook’s machines collect trillions of datapoints every day, then process and apply them, without humans in the loop. Of course, their researchers do human-scale research to diagnose how the algorithm is functioning, and can change both the data that are sensed and the algorithms that are used. But it’s very much not the case that Facebook researchers have a real-time supervised learning model that tells them the (say) partisan leanings of everything in a given user’s feed so that a human can approve or reject every novel possible media link. This is straightforwardly impossible due to the constraints of human cognition. But it’s not an unfair analogy to the current structure of quantitative social science.
The only difference is the respective goals of these enterprises. Facebook wants to maximize long-term profits, obviously, but they still need to have humans decide on the relationship between those profits and the metrics generated by their system (most likely, attention via time on platform). The goal of social science is less directly obvious. We want to understand the world, of course, but we don’t have a well-defined optimand that tells us when we’re succeeding or not.
Here’s a possible re-orientation. Progress in natural science comes along with better scientific instruments. Astronomy without telescopes can only get so far. We can think of all of the steps of knowledge production as a machine; the more integrated that machine is, the better we can use it for our knowledge-generating ends.
Danger Zone: What Follows is Beyond my Philosophical Skill
Over the pandemic, I’ve been diving into the discipline of Cybernetics. I happened upon Norber Wiener’s epochal work with that title in a used book store and was energized by the way it connected previously disparate parts of my thinking. Cybernetics then kept appearing in different areas of intellectual life that I found important; Jill Lepore’s recent book on the Simulatics Corporation and the founding of postwar behavioral science; Quinn Slobodian’s intellectual history of Globalism; Mark Fisher’s early work in political theory-fiction; and most explicitly, in Andrew Pickering’s intellectual history of cybernetics.
The latter has been revelatory. It explicitly describes an alternative kind of machine intelligence than the “centralized AI” (aka GOFAI, or Good Old-Fashioned AI) that dominates the current model. The essential move, they say, is to de-center knowledge.
Pickering describes the development of the philosophy of quantitative social science as too focused on epistemology at the expense of ontology. I’ve been confused by the latter term basically every time I’ve encountered it over my adult life, but this book made it make sense.
First…ontology (both the term and its implied approach) has in fact been growing in popularity over the past decade, moving from philosophy to the critical humanities. I have best been able to understand it as a “de-centering of the human,” both as a unit of analysis (part of the broad development of Actor-Network Theory) and as an actor. The latter, in the current case, means something like the “science without scientists” I develop in this article. This science, Pickering argues, cannot be purely representational or abstract; it has to be performative, it has to immediately act in the world.
The germ of this idea can be found in Wiener’s foundational Cybernetics, which was famously first applied in the development of anti-aircraft guns during World War II. This wasn’t science, so the human limitation was not the amount of data required to shoot a moving plane but rather the speed at which we have to adjust. At human speeds, our brains and bodies act in tandem; we observe the barrel of the gun move in response to our willing it to move, see the target move with our eyes, and then sync these up. At machine speeds, this feedback/equilibrium process happens much too quickly. For cybernetic range finders to operate, they have to enhance the human processing loop by containing information about how aircraft can move. Human snipers check the windspeed and adjust for gravity, but they are ultimately the locus of knowledge synthesis; for anti-aircraft, however,
“The chain of operation has to work too fast to admit of any human links” (p61).
This concept is advanced further in Pickering, applied specifically to science:
“The hallmark of cybernetics was a refusal of the detour through knowledge” (p21).
Emphasis added. This is where I’m at right now. The goal of social science is prediction (at least for some people); prediction is an action. The modern epistemology of science sees actions as a consequence of representational knowledge (the kind of thing that’s in your brain). But this is a mistake; we can have actions without knowledge.
Over the past two decades, in fact, the overwhelming majority of actions that would previously have only been possible through knowledge have been taken without knowledge. The recommendation systems are the best example, but consider also the algorithmically-generated music we listen to and automated stock market trading.
This approach, of science without scientists making predictions without knowledge, seems like the only way to keep up with the dimensionality and speed of the contemporary social world. Is this ultimately a good thing, is it ultimately worth doing? I have no idea.
But that ship has sailed; it’s already being done, within all the major tech companies that each have more data about human behavior and more compute power than all public academic research combined. Weiner saw all of this coming, over sixty years ago:

I think his diagnosis is correct, both in the inevitability of continuing (accelerating) developments and in the humanist path forward for social scientists.